监控平台应用背景
监控平台被形象地称为运维之眼,没有它软件产品的上线及后期维护将像摸虾一样。
从监控的对象来划分,监控又可分为基础监控和业务监控。
基础监控偏重基础组件和基础资源的监控,一般指标比较固定,很大程度上可默认采集。
业务监控偏重具体服务的指标监控,较为灵活,一般为具体业务自己定义。
监控平台在整个上线的各个过程中都是有帮助的,它使用的场合有以下几项:
- 提供服务上线的参考,如可观察新特性上线后的各项指标是否正常,作为稳定运行的依据
- 出现事故后,可作为定位问题的参考,让排查问题更方便
- 监控服务及资源的使用情况,为优化或扩容做准备
其中,12基础监控和业务监控兼有,一般方式为基础监控缩小范围,业务监控更准确地查找。业务监控一般会配合日志平台一起提供帮助。
3涉及到具体IaaS层资源,基础监控可以提供更多帮助。
常见架构设计
市面监控平台多以agent上报的方式采集数据,由于监控平台写多读少的缘故,上报链路中间多可插入一个消息队列或代理。
由于采集端已有监控数据,告警平台多与监控平台整合,这样一个采集,一个消费,就会方便很多。
open-falcon
open-falcon是小米的监控平台,open-falcon之前,小米使用的是zabbix。
open-falcon的架构图如下所示:
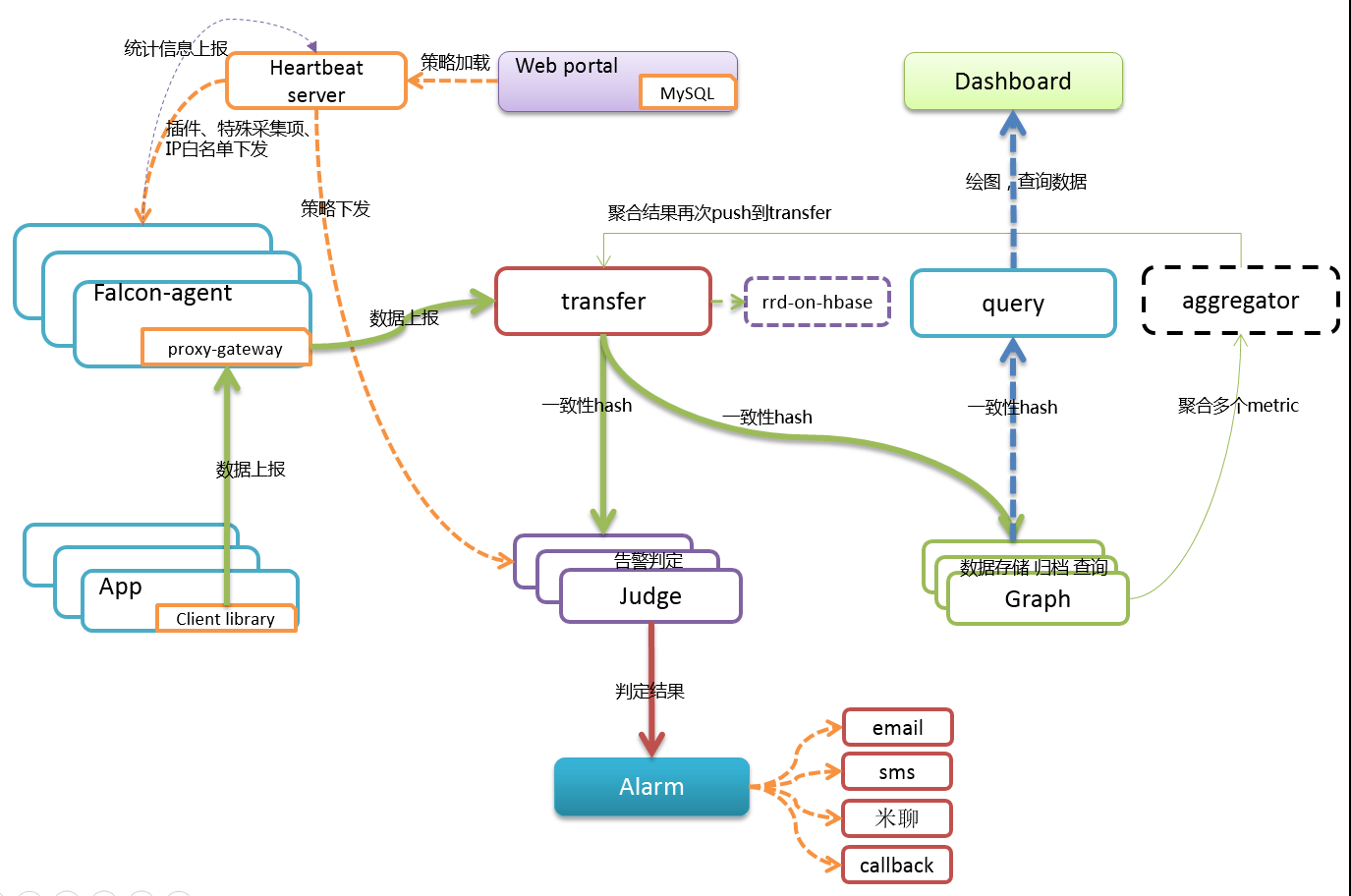
乍一看挺复杂,捊一捊就比较清晰了。
数据上报链路:绿色粗线即为数据上报链路,数据从App产生或由agent采集,然后发送到transfer,transfer再将数据分发给judge和graph。judge即为告警判定模块,graph存储监控数据。
配置下发链路:橙色虚线为配置下发链接,portal为配置存储中心。为了加速配置的下发,同时减小portal的压力,hbs会将portal缓存一份到自己的内存,在需要的时候会下发给agent(监控配置)和judge(告警配置)。
监控查看链路:蓝色虚线部分为监控查看链路,graph是监控数据的存储组件,出于负载均衡的考虑,graph可能有多个实例,query组件负责整合多个实例的结果,供dashboard读取。dashboard为通往用户的web界面。
open-falcon中的大部分组件都是可以水平扩展的,transfer、judge和graph都是可能会出现瓶颈的组件。官网有一个机器量与瓶颈及应对的对应关系,很有参考价值。
agent 采集上报
agent 是数据采集和上报端,更接近数据,比较重要。
agent 默认已提供机器的大部分基础监控,modules/funcs/ 下可以看到监控的列表,cpu、内存、磁盘、负载、网络io等,涵盖了绝大部分机器相关监控。
agent 每隔一段会将 metrics 上报到 transfer,metrics 是一个列表,下面是一个比较典型的 metric 结构:
1 | type MetricValue struct { |
这里说一下 Type,主要有 GAUGE 和 COUNTER 两种。GAUGE 为实际的测量值,如内存使用率;COUNTER 为计数值,上报时会计算差值,比较典型的如磁盘读请求次数(linux内核提供的值为总计,我们希望了解的是上一分钟及这一分钟的读请求次数)。
在扩展性方面,agent 还提供了另外两种采集方式,http push 上报的方式和 plugin 采集。这两种方式都是以 MetricValue 为上报的基础数据结构。
push 方式,agent 会在本机提供一个 http 服务,应用可将数据以 http 请求的方式上报给 agent。http 提供了很大的灵活性,应用可整合上报功能来集成业务监控。
plugin 方式,需要提供一个包含采集脚本的仓库。所谓采集脚本,即是指本地可运行的脚本,该脚本会输出 MetricValue 结构的 json 数据,agent 将定期执行并将输出上报给 transfer。
下面是官方提供的一个 python 采集脚本:
1 | # https://github.com/open-falcon/plugin/blob/master/demo/60_plugin.py |
NOTE: 需要注意的是,为了避免 plugin 全量上报造成干扰,plugin 上报需要在 dashboard/portal 中指定启用哪些上报脚本。
第三方监控多以 push 方式上报,有了上面两种扩展的上报方式,即可以实现其它基础监控或者业务监控。
总结
open-falcon 算是国内比较成熟的监控产品,虽说多组件的方式部署可能较为庞杂,但 falcon-plus 对 open-falcon 的组件做了整合,部署难度已经下降了好几个数量级,安装已经不再是大问题。
open-falcon 以 golang 和 python 为主要开发语言。提供水平扩展的组件多为 golang 开发,可单独打包,降低了部署的难度;web 端以 python 为主,开发效率较高。各取所长。组件粒度较细,解耦也较彻底,二次开发难度较小。
push 上报方式是许多监控产品采用的方式,较为灵活通用,可满足扩展的需要。其它监控如 mysql 或者具体业务的监控等也可基于此方式实现。
另外,open-falcon 组件内部多使用 rpc 协议沟通,效率也是比较高的。有时间再展开写一写。
除了监控数据,另一块是告警判定逻辑。后面来补充。